So, it seems I have reached my first goal since the Great Turning Point this summer: today I received my certification for the data analyst nanodegree on Udacity. It was not the greatest challenge of all times, nevertheless it feels good to pass even such a smaller milestone.
It took little longer than I anticipated, even when accounting for the short summer holiday, but as I didn’t have any previous examples, my first guess was not a reliable benchmark anyway. I managed to fit the whole thing into two months, and still have some life besides learning.

What did I learn?
Even though I considered this course a ’refresher’, I did learn quite a few new things. Here are the key takeaways:
- This was a good idea: After spending the better part of the summer with data crunching, coding stats and drawing charts, I am even more excited about all these things than before. The experiment was succesful, the subject is still alive!
- Refreshed theoretical background: Though I learnt lots of stats and econometrics (I’m an economist and investment analyst after all), I haven’t been using that in the past few years as a manager. Now I have some working knowledge again and a general understanding of the directions I am yet to explore.
- Practical Python skills: I already used tools like
pandas,scipy,pyplotor Jupyter notebooks before, but I explored them even further. I am considerably faster now and write code in a more pythonic way. - New tools: I never tried R before, and even though I had my fair share of struggles with it, I think I see where it fits into the data science world. Also since I finished my project with Tableau I just keep asking myself ’Why didn’t I use this before?’. I will write about this later.
- Sneak peek into Machine Learning: That was the main goal: take a look into this enormous field without getting too deep, too fast. It worked and now I have a more nuanced overview in general, I can translate (some) questions into (basic) machine learning problems, and I have practical understanding of
scikit-learn. - Realizing how much I don’t know: I had nice revelations and felt success along the way, but the most important takeaway is that I am still just scracthing the surface of data science (and especially machine learning). But the good news is that I have all the means to dig deeper!
I think I will write at least one or two mosre posts about the actual projects and share the results in some form.
How long did it take?
During the two months from July 11 to September 13, I have spent close to 140 hours in total with the course materials and completing the projects (I tracked time with Harvest and its Trello power-up). This all translates to more than 15 hours a week, slightly, but not disapointingly less than I initially planned for.
This is the actual (net) time I was working on the course (or tried very hard), not including casual reading in the subject, playing with the new tools on my own, or writing blog posts about it. Unfortunately I did not measure the projects separately from their courses, but for most of the modules the ‘homework’ took the majority of the time.
Obviously Intro to Machine Learning was the most complex one, and also the course materials were quite lengthy. I spent at 30 hours of it on the project trying to predict which stakeholder might be a person of interest in the famous Enron fraud case by using some financial data and their emailing statistics. That was challenging for me, but enjoyed it (most of the time).
The Exploratory Data Analysis also took long (28 hours), but this was more about the tool than the content. It was mandatory to complete the project in R and RStudio. The other modules can be finished in a matter of week or even a in a few days.
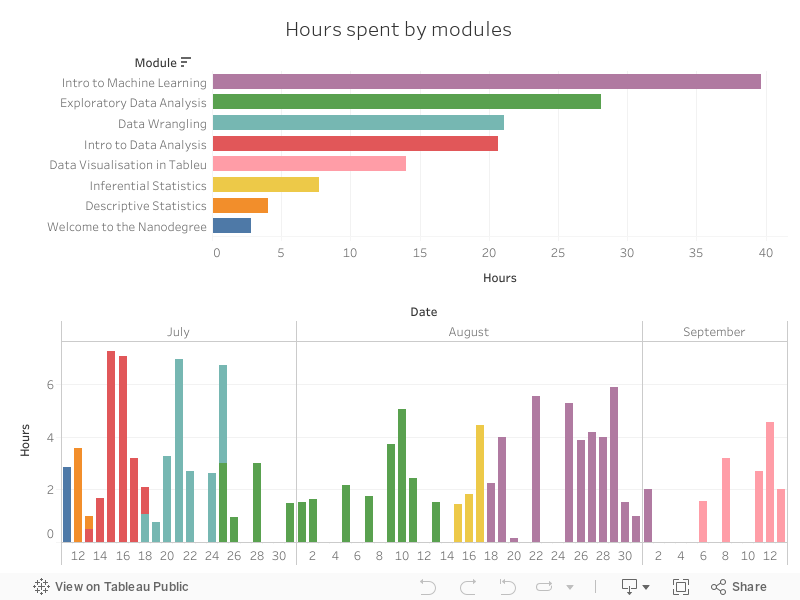
It’s also interesting to see how my enthusiasm decreased during the time: I started with spending at least a few hours on the nanodegree for 12 consecutive days, sometimes clocking in even 6-7 hours, jumping into the next project the same day I passed the previous. I only missed four days out of 20.
But that’s exhausting, and does not leave much room for other activites. The pace of the second half of August seems more sustainable, leaving out a few days, and only putting in around 4 hours a day when doing longer streaks. I guess that’s what I should be aiming for in the future.
What would I do differently?
In general I’m satisfied how it went. In hindsight I might have spent more time on the course materials than it was absolutely necessary, because I didn’t want to miss any important parts (I was playing the videos on 1.25x or 1.5x speed anyway). But I think my future courses will be more difficult, so this is not going to be an issue anymore.
Also for a few projects I felt I put in more than the minimum requirements (even though not all my projects met expectations for the first submission). But my goal was to learn these things, not to barely pass as fast as I can, so none of the extra hours were wasted (and I am not even sure there were that many ‘extra’ hours, maybe that’s exactly what it takes to complete these things).
What’s next?
My plans have not changed much, I am aiming for the Machine Learning nanodegree on Udacity. I think it will need much more time than the Data Analyst Nanodegree, but I haven’t done any estimations yet. But before that I need a little break (a few days maybe a week) to catch up on some other private projects I was ignoring in the past few weeks.
If you happen to have any experiences with similar courses, share it! I’m very open to feedback.